본 게시글은 내일배움카드로 신청한 패스트캠퍼스의 국비지원교육 강의: SQL 데이터 분석 첫걸음입니다.
본 게시글은 패스트캠퍼스의 열공 챌린지 형식을 준수하며, 개인적인 정리 목적으로 학습 내용을 정리한 글입니다.
- 제목, 본문, 해쉬태그 키워드 포함
- 사진 1장 이상, 글자수 500자 이상 (공백 포함, 코드 제외)
강의 자료: https://drive.google.com/drive/folders/10dkcpVSTAZsH8__dDp8aKwfS0GCnUXXH
DAY 21
마지막 날에는 내용을 총 정리하는 관점에서 해커톤 프로젝트를 진행한다.
프로젝트 개괄은 다음과 같다.

STEP 1: DB 환경 구축
/*
* SET SCHEMA
*/
DROP DATABASE IF EXISTS fastcampus_final;
CREATE DATABASE IF NOT EXISTS fastcampus_final;
SHOW DATABASES;
USE fastcampus_final;이후 LOAD DATE를 활용하여 로컬 파일을 테이블에 적재할텐데,
그 전에 데이터를 수용할 수 있도록 테이블에 대한 정의가 필요하여 데이터 형식을 확인하는 작업을 시작하였다.
STEP 2: 데이터 형식 확인
다루어야 할 데이터가 이미 잘 정돈된 정형 데이터이기 때문에 별도의 변환 없이 Excel에서 바로 초기 분석을 진행한다.
[ Excel 분석 과정 ]
Excel에서 Len() 함수는 특정 셀의 문자열 길이를 반환한다.
이런 Len 함수의 인자로 셀이 아닌 범위를 전달하고, 수식을 중괄호 { }로 묶으면 배열 수식이 적용된다.
(배열 수식은 Ctrl + Shift + Enter로 적용이 바로 가능하기 때문에, 앞 글자만 따서 CSE 수식으로도 불린다.)
아래 수식을 통해 주어진 필드의 최대 문자열의 길이를 조사할 수 있다.
(숫자형 데이터도 문자열 취급하여 숫자의 개수를 센다.)
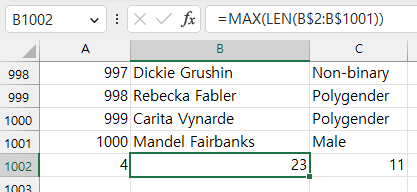
데이터 중 숫자에 대해서는 최솟값 / 최댓값을 조사하는 과정이 필요하다.
MIN / MAX 함수는 기본적으로 범위 인자를 지원하는 함수이므로 다음과 같이 조사가 가능하다.
결과값을 통해 선택된 customers.age에서 연령 데이터는 20세부터 80세까지 존재함을 알 수 있다.

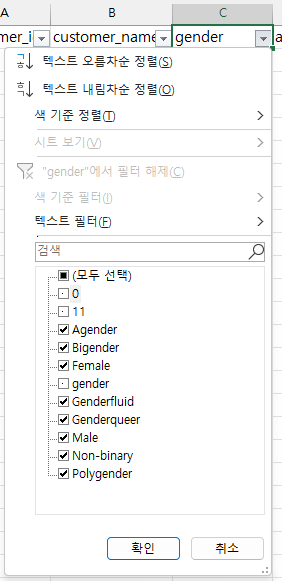
customers.gender는 비슷한 값이 반복되는 것으로 보아 범주형 데이터인 것 같다.
그 종류를 조사하기 위해 필드명에 필터를 걸었다.
앞서 분석을 위해 이어 적은 gender, 11, 0, 0 데이터를 제외하면, 값은 대문자로 시작하며, 총 8종이다.
customers.city도 왠지 비슷한 값이 반복될 것 같아 보이는데, 중복이 있는지는 확실하지 않다.
고유값 조사를 위해 데이터 > 데이터 도구 > 중복된 항목 제거를 해당 범위에 적용한다.
여기서는 각 필드에 대한 중복만 확인하기 때문에 영역은 확장할 필요가 없다.
범위를 잡을 때, 필드명과 함께 잡았다면, 머리글 표시를 체크해준다.
결과창을 통해 39개의 중복된 레코드와 961개의 고유값의 합이 총 레코드 수 1000개와 같음을 확인한다.
이후 Ctrl + z를 눌러 원상복귀한다.


orders
다음은 위 과정을 거쳐 분석한 데이터 형식을 정리한 내용이다.
이 내용을 바탕으로 테이블을 정의하고, 데이터를 적재하려 한다.
1. customers.csv
[ 9 fields * 1000 records ]
1-1. customer_id: INT [1, 1000]
** orders.csv의 필드와 연동
1-2. customer_name: VARCHAR(23+)
formatted: first_name + (space) + last_name
1-3. gender: VARCHAR(11+)
categorical [N = 8: Agender, Bigender, Female, Genderfluid, Genderqueer, Male, Non-binary, Polygender]
1-4. age: INT [20, 80]
1-5. home_address: VARCHAR(33+)
formatted: INT + STRING + INT separated by (space)
1-6. zip_code: INT [2, 9998]
1-7. city: VARCHAR(22+)
categorical( sparse ) [N=961: Aaronbury, Abbeyshire, Abbeyview, Abbottburgh, ... ]
1-8. state: VARCHAR(28+)
categorical [N=8: Australian Capital Territory, New South Wales, Northern Territory, Queensland, South Australia, Tasmania, Victoria, Western Australia]
1-9. country: VARCHAR(9+)
categorical [N=1: Australia ]
2. orders.csv
[ 5 fields * 1000 records ]
2-1. order_id: INT [1, 1000]
2-2. customer_id: INT [1, 1000]
** customers.csv의 필드와 연동
2-3. payment: INT [10043, 59910]
** 정확한 정보는 주어지지 않았으나, 각 구매기록 별 지불 금액을 의미하는 변수로 추정
2-4. order_date: CHAR(10)
formatted: year(4 digit), month, day separated by (hiphen)
2-5. delivery_date: CHAR(10)
formatted: year(4 digit), month, day separated by (hiphen)
STEP 3: 테이블 생성
상기한 데이터 형식 정의에 따라 테이블을 생성한다.
/*
* CREATE TABLE
*/
DROP TABLE IF EXISTS tbl_customers;
CREATE TABLE IF NOT EXISTS tbl_customers (
customer_id INT
,customer_name VARCHAR(23)
,gender VARCHAR(11)
,age INT
,home_address VARCHAR(33)
,zip_code INT
,city VARCHAR(22)
,state VARCHAR(28)
,country VARCHAR(9)
);
DROP TABLE IF EXISTS tbl_orders;
CREATE TABLE IF NOT EXISTS tbl_orders (
order_id INT
,customer_id INT
,payment INT
,order_date CHAR(10)
,delivery_date CHAR(10)
);
SHOW TABLES;
STEP 4: 데이터 적재
MySQL Workbench LOAD DATA LOCAL INFILE ERROR (tistory.com)
기존 게시글에 정리해둔 내용을 바탕으로 데이터를 적재한다.
/*
* LOAD DATA
*/
SET GLOBAL local_infile = TRUE;
LOAD DATA LOCAL INFILE "C:/Users/user/Documents/prac/sqlPrac/source/final_customers.csv"
INTO TABLE tbl_customers
FIELDS TERMINATED BY ","
IGNORE 1 LINES;
LOAD DATA LOCAL INFILE "C:/Users/user/Documents/prac/sqlPrac/source/final_orders.csv"
INTO TABLE tbl_orders
FIELDS TERMINATED BY ","
IGNORE 1 LINES;
-- CHECK RESULT
SELECT count(*) FROM tbl_customers
UNION ALL
SELECT count(*) FROM tbl_orders;
SET GLOBAL local_infile = FALSE;
SHOW GLOBAL VARIABLES LIKE 'local_infile';


점심 식사 및 1시간 휴식
MISSION #1: 고객의 등급 구분
1-1. [ 총 구매횟수, 총 구매금액, 평균 구매금액 ] 중 하나의 기준을 선택한다.
1-2. 고객의 서비스 이용 데이터를 토대로 해당 기준에 대한 값을 산출한다.
1-3. 결과값을 토대로 고객을 5개 등급으로 구분한다. ( std_rate = 1 to 5 )
1-4. std_rate = 1인 고객에 대한 ( std_rank, customer_id, customer_name, gender, age, address, std )를 출력한다.
1-1. 기준으로 총 구매금액을 선택했다.
왜냐하면 매출액의 관점에서 가장 설명력이 높은 기준이라고 생각했기 때문이다.

1-3. 결과값을 토대로 고객을 5개 등급으로 구분한다. ( std_rate = 1 to 5 )
초기에는 주어진 617명의 고객들의 총 구매금액의 순위에 따라 5등분하여 각 등급에 약 123명이 들어가도록 하는 것보다,
총 구매금액의 평균과 표준편차를 고려하면 구매력이 더 높은 고객의 등급을 선별할 수 있을 것이라고 생각했다.
하지만 이상치가 통계량에 미치는 영향을 고려하기 시작하면 모델이 굉장히 복잡해지므로,
현재 주어진 자료를 토대로 분석하여, 다소 직관적인 결정으로 마무리하기로 했다.

1. 히스토그램: 빨간색으로 표시된 revenue <= 59,414를 기점으로 하위 66%와 상위 33%가 구분된다.
하위 구간은 중요하지 않으니 2개 등급으로 구분하고, 이 상위 33% 구간을 세 개로 나누어야겠다.
2. 누적 꺾은 선: 로렌츠 곡선과 지니 계수에 착안한 시각화이다. 두 선의 차이에 비례하여 구매금액의 양극화가 심화된다.
이 부분은 서로 다른 시간으로 집계된 통계 자료를 비교할 때 더 의미가 있을 것 같아 설명은 생략하겠다.
3. 박스 플롯: revenue > 135,168를 만족하는 고객의 수는 총 14명이다.
계산 결과, 전체 고객 617명 중 상위 2%고객의 총 구매금액이 전체 매출의 약 7%를 차지하고 있었다.
대부분의 구매는 [ 28422, 71161 ] 구간에서 이루어졌다.
=> 본 자료를 토대로 5개의 구간은 각각 총 구매금액의 상위 11, 22, 33, 66% 그리고 나머지로 나누기로 결정하였다.
SET @v_total_rows = (SELECT count(DISTINCT customer_id) FROM tbl_orders);
SELECT @v_total_rows;
CREATE TABLE tbl_revenue
SELECT
customer_id
,revenue
,CASE
WHEN rank_revenue * 100 <= 11 * @v_total_rows THEN 1
WHEN rank_revenue * 100 <= 22 * @v_total_rows THEN 2
WHEN rank_revenue * 100 <= 33 * @v_total_rows THEN 3
WHEN rank_revenue * 100 <= 66 * @v_total_rows THEN 4
ELSE 5 END AS rate_revenue
FROM (
SELECT
DISTINCT customer_id
,sum(payment) AS revenue
,DENSE_RANK() OVER(ORDER BY sum(payment) DESC) AS rank_revenue
FROM tbl_orders
GROUP BY 1
) AS T
GROUP BY 1;
SELECT * FROM tbl_revenue;

1-4. std_rate = 1인 고객에 대한 ( std_rank, customer_id, customer_name, gender, age, address, std )를 출력한다.
SELECT
A.rate_revenue
,A.customer_id
,B.customer_name
,B.gender
,B.age
,B.home_address
,A.revenue
FROM tbl_revenue AS A
LEFT JOIN tbl_customers AS B
ON A.customer_id = B.customer_id;

MISSION #2: KPI 지표
** 서비스를 평가할 수 있고, 그에 따른 인사이트를 얻을 수 있는 지표를 출력하시오.
MISSION #1에서 분류한 고객 등급을 기준으로 고객군의 재구매 주기의 평균을 조사해보자.
[ 시행 착오 ]
SELECT
rate_revenue
,avg(avg_rebuy) AS avg_datediff_rebuy
FROM (
SELECT
A.customer_id
,A.rate_revenue
,round(
datediff(
max(date_format(B.order_date, "%Y-%m-%d"))
,min(date_format(B.order_date, "%Y-%m-%d"))
) / count(*)
, 2) AS avg_rebuy
FROM tbl_revenue AS A
LEFT JOIN tbl_orders AS B
ON A.customer_id = B.customer_id
GROUP BY 1,2
) AS T
GROUP BY 1
ORDER BY 1;
흥미로운 결과가 나왔다.총 구매금액이 높은 상위 33%의 세 그룹은 평균적으로 재구매에 약 50일 정도의 시간이 소요되는 반면,총 구매금액이 낮은 그룹으로 갈수록 재구매 주기가 짧아진다는 사실이 확인되었다.
사실 확인을 해보니, rate = 5인 그룹은 재구매 기록이 없는데,
그 사실이 반영이 안 되어 평균이 작게 산출된 것이었다.
WHERE 절만 추가하니 해결되었다.
-- RESULT
SELECT
rate_revenue
,avg(avg_rebuy) AS avg_datediff_rebuy
,count(*)
FROM (
SELECT
A.customer_id
,A.rate_revenue
,round(
datediff(
max(date_format(B.order_date, "%Y-%m-%d"))
,min(date_format(B.order_date, "%Y-%m-%d"))
) / count(*)
, 2) AS avg_rebuy
FROM tbl_revenue AS A
LEFT JOIN tbl_orders AS B
ON A.customer_id = B.customer_id
GROUP BY 1,2
) AS T
WHERE avg_rebuy > 0
GROUP BY 1
ORDER BY 1;
상위 33%에 해당하는 1~3 rate의 그룹은 재구매 빈도가 상당히 유사한 성격을 띠고 있었다.
rate = 5 그룹은 서로 다른 client들의 일회성 구매 빈도가 높을뿐, 재구매 기록은 별로 없음을 알 수 있었다.
이와 같은 영향은 아마 첫 구매 프로모션 등의 영향에 따른 결과일 수도 있다.
마치며...
SQL의 세계에는 아직 내가 접해보지 못한 신기한 테크닉들이 많이 존재하고 있다.
이번 교육을 계기로 그 포문을 연 것 같아서 마음이 가볍다.
이후 이어지는 SQLD 시험도 가벼운 마음으로 경험차 준비하고자 한다.
'Learn' 카테고리의 다른 글
| [패스트캠퍼스: Java&Spring 웹 개발] Week 3 - Java OOP Advanced (0) | 2023.06.14 |
|---|---|
| [패스트캠퍼스: Java&Spring 웹 개발] Week 2 - OOP Basic (0) | 2023.06.12 |
| [패스트캠퍼스: SQL 데이터 분석 첫걸음] Week 4 - SQL 실무 감각 익히기 (0) | 2023.06.05 |
| [패스트캠퍼스: SQL 데이터 분석 첫걸음] Week 3 - SQL 고급 기능 익히기 (0) | 2023.05.30 |
| [패스트캠퍼스: SQL 데이터 분석 첫걸음] Week 2 - SQL을 활용해 데이터 다루기 (0) | 2023.05.25 |