본 게시글은 내일배움카드로 신청한 패스트캠퍼스의 국비지원교육 강의: SQL 데이터 분석 첫걸음입니다.
본 게시글은 패스트캠퍼스의 열공 챌린지 형식을 준수하며, 개인적인 정리 목적으로 학습 내용을 정리한 글입니다.
- 제목, 본문, 해쉬태그 키워드 포함
- 사진 1장 이상, 글자수 500자 이상 (공백 포함, 코드 제외)
강의 자료: https://drive.google.com/drive/folders/1ucC9qR5ca-EOd7T8jZY0pQrVoJxtUfs5
DAY 13
실습 초기 세팅
MySQL Workbench 내부 Data Import Wizard를 활용하여 csv 파일을 테이블로 변환하려는데,
속도가 매 ───── 우 느리다...
4개의 필드를 가진 csv 파일을 업로드하는데, 2초에 10개의 row만 삽입되고 있었다.
심지어 병렬 작업도 불가능해서 다른 방법을 찾아보기로 했다.
** MySQL에서 LOAD DATA 문을 활용하여 1초만에 데이터를 테이블에 적재하는 과정을 별도의 포스팅으로 정리해두었다.
이 방법을 사용하면 몇 십만개의 레코드도 몇 초만에 적재가 가능하다. (기존 마법사 대비 만 배 이상의 성능)
MySQL Workbench LOAD DATA LOCAL INFILE ERROR (tistory.com)
MySQL Workbench LOAD DATA LOCAL INFILE ERROR
배경 csv 형식의 데이터를 테이블로 적재하는 과정 중 내장된 Import Wizard의 성능 이슈로 다른 방법을 모색 중, 초기 설정의 workbench에서는 보안적인 이유로 제한되는 LOAD DATA LOCAL INFILE 문을 활용하
spems.tistory.com
SHOW DATABASES;
USE fastcampus;
SHOW TABLES;
/*
* START IMPORT CSV FILE
*/
SET GLOBAL local_infile = TRUE;
/*
* TABLE: tbl_customer
*/
DROP TABLE IF EXISTS fastcampus.tbl_customer;
CREATE TABLE IF NOT EXISTS fastcampus.tbl_customer (
customer_id INT PRIMARY KEY,
created_at CHAR(25),
gender VARCHAR(6),
age INT
);
LOAD DATA LOCAL INFILE "C:/Users/user/Documents/prac/sqlPrac/source/tbl_customer.csv"
INTO TABLE fastcampus.tbl_customer FIELDS TERMINATED BY ",";
DELETE FROM tbl_customer WHERE customer_id = 0;
SHOW TABLES;
SELECT * FROM tbl_customer;
/*
* TABLE: tbl_purchase
*/
DROP TABLE IF EXISTS fastcampus.tbl_purchase;
CREATE TABLE IF NOT EXISTS fastcampus.tbl_purchase (
id INT PRIMARY KEY,
customer_id INT,
purchased_at CHAR(25),
category VARCHAR(20),
product_id VARCHAR(20),
price INT
);
LOAD DATA LOCAL INFILE "C:/Users/user/Documents/prac/sqlPrac/source/tbl_purchase.csv"
INTO TABLE fastcampus.tbl_purchase FIELDS TERMINATED BY ",";
DELETE FROM tbl_purchase WHERE id = 0;
SHOW TABLES;
SELECT * FROM tbl_purchase;
/*
* TABLE: tbl_visit
*/
DROP TABLE IF EXISTS fastcampus.tbl_visit;
CREATE TABLE IF NOT EXISTS fastcampus.tbl_visit (
id INT PRIMARY KEY,
customer_id INT,
visited_at CHAR(25)
);
LOAD DATA LOCAL INFILE "C:/Users/user/Documents/prac/sqlPrac/source/tbl_visit.csv"
INTO TABLE fastcampus.tbl_visit FIELDS TERMINATED BY ",";
DELETE FROM tbl_visit WHERE id = 0;
SHOW TABLES;
SELECT * FROM tbl_visit;
/*
* END IMPORT LOCAL FILES
*/
SET GLOBAL local_infile = FALSE;
SHOW GLOBAL VARIABLES LIKE 'local_infile';** Excel을 활용하여 csv 데이터 format을 확인했고, 다행히 주어진 게 정형 데이터라 (설정한 PK의 값) = 0 조건을 통해 변수명 타입 캐스팅 간 잘못 입력된 데이터를 삭제할 수 있었다.
** LOAD DATA LOCAL INFILE문의 용법과 내용은 위 포스팅에서 따로 다루겠다.
실습
-- SHOW DATABASES;
USE fastcampus;
-- SHOW TABLES;
SELECT * FROM tbl_customer LIMIT 100;
SELECT * FROM tbl_purchase LIMIT 100;
SELECT * FROM tbl_visit LIMIT 100;
/*
* Q1. 2020년 7월의 REVENUE (수입; sum(price))
*/
-- REVENUE = sum(price.purchased_at:2020.7.xx)
-- SELECT * FROM tbl_purchase WHERE left(purchased_at, 7) = "2020-07";
SELECT sum(price) AS "revenue_2020-07" FROM tbl_purchase WHERE left(purchased_at, 7) = "2020-07";
SELECT sum(price) AS "revenue_2020-07" FROM tbl_purchase
WHERE purchased_at BETWEEN '2020-07-01' AND '2020-08-01';
/*
* Q2. 2020년 7월의 MAU(Monthly Active Users: 월간 방문 순수 사용자 수)
*/
-- SELECT * FROM tbl_visit WHERE left(visited_at, 7) = "2020-07"; -- nRows: 126466
-- SELECT DISTINCT id FROM tbl_visit WHERE left(visited_at, 7) = "2020-07"; -- nRows:126466, id는 잠재적 중복 가능성 배제를 위한, INCREMENT와 같은 느낌의 필드
SELECT count(DISTINCT customer_id) FROM tbl_visit WHERE left(visited_at, 7) = "2020-07"; -- nRows:16414
/*
* Q3. 7월의 Active User 구매율 (구매/방문)
*/
-- SELECT count(DISTINCT customer_id) FROM tbl_visit WHERE visited_at LIKE "____-07%";
-- SELECT count(DISTINCT customer_id) FROM tbl_purchase WHERE purchased_at LIKE "____-07%";
SELECT
round(
(SELECT count(DISTINCT customer_id) FROM tbl_purchase WHERE purchased_at LIKE "____-07%") /
(SELECT count(DISTINCT customer_id) FROM tbl_visit WHERE visited_at LIKE "____-07%") * 100
,2) AS "active_user_purchase_rate_2020-07 (%)";
/*
* Q4. 7월 구매 유저의 월 평균 지출(구매) 금액 (ARPPU: Average Revenue per Paying User)
* STEP 1. 7월 구매 유저
* STEP 2. 각 유저들의 지출(구매) 금액 평균
*/
-- 7월의 각 구매 기록에 대한 평균 매출액은 다음과 같이 구할 수 있다.
-- SELECT avg(price) FROM tbl_purchase
-- WHERE customer_id IN (
-- SELECT DISTINCT customer_id FROM tbl_purchase WHERE purchased_at LIKE "____-07%"
-- );
-- 출제자의 의도는 '구매 금액 평균'이라는 것이 각 구매 단가에 대한 평균이 아니라, 각 소비자의 소비 총액의 평균을 뜻하는 것이었다.
SELECT avg(T.revenue) AS revenue_for_each_customer_at_XX_07
FROM (
SELECT sum(price) AS revenue FROM tbl_purchase
WHERE purchased_at LIKE "____-07%" GROUP BY customer_id) AS T;
/*
* Q5. 7월 구매 빈도 Top3, Top10~15
*/
-- SELECT * FROM tbl_purchase WHERE purchased_at LIKE "____-07%";
-- SELECT customer_id, count(customer_id) FROM tbl_purchase WHERE purchased_at LIKE "____-07%" GROUP BY customer_id;
-- SELECT
-- customer_id,
-- RANK() OVER (ORDER BY count(customer_id) DESC) AS purchase_rank
-- FROM tbl_purchase
-- WHERE purchased_at LIKE "____-07%"
-- GROUP BY customer_id;
SELECT customer_id, purchase_rank FROM (
SELECT
customer_id,
RANK() OVER (ORDER BY count(customer_id) DESC) AS purchase_rank
FROM tbl_purchase
WHERE purchased_at LIKE "____-07%"
GROUP BY customer_id
) AS T
WHERE
T.purchase_rank = 3 OR
T.purchase_rank BETWEEN 10 AND 15;
-- 키워드 limit, offset을 활용하여 연속된 레코드에 대한 슬라이싱이 가능하다DAY 14
시간과 날짜에 대한 데이터를 다루는 것은 실무에서 빠지지 않아 중요하다.
하지만 SQL 언어 종류에 따라 다루는 방법에 차이가 있어서 경력자들도 헷갈리는 경우가 있다고 한다.
기본적인 예제부터 학습해보자.
-- Date Format 함수
SELECT now(); -- 2023-06-01 07:43:41
SELECT current_date(); -- 2023-06-01
SELECT extract(MONTH FROM now()); -- 6
SELECT day(now()); -- 1
SELECT date_add(now(), INTERVAL 7 DAY); -- 2023-06-08 07:48:26 (7일 후)
SELECT date_sub(now(), INTERVAL 7 DAY); -- 2023-05-25 07:48:51 (7일 전)
SELECT datediff(now(), date_add(now(), INTERVAL 7 DAY)); -- -7 (A-B; 절댓값이 아님)
SELECT date_format(now(), "%Y-%m-%d %T");
SELECT time(now());
SELECT timediff(now(), date_format(now(), "%Y-%m-%d %T"));날짜/시간 데이터에 대해 day 함수를 적용할 때, 지역 시차에 따라 데이터 값이 변하는 현상이 발생한다.
이는 데이터에 시차가 명시되어 있지 않기 때문에 발생하는 오류이다.
이를 수정하는 방법은 다양하지만, 날짜/시간 함수 대신 substring으로 충분히 대체할 수 있다.
/*
* Date Format 함수 사용 예제
*/
-- SELECT now(); -- 2023-06-01 07:43:41
-- SELECT current_date(); -- 2023-06-01
-- SELECT extract(MONTH FROM now()); -- 6
-- SELECT day(now()); -- 1
-- SELECT date_add(now(), INTERVAL 7 DAY); -- 2023-06-08 07:48:26 (7일 후)
-- SELECT date_sub(now(), INTERVAL 7 DAY); -- 2023-05-25 07:48:51 (7일 전)
-- SELECT datediff(now(), date_add(now(), INTERVAL 7 DAY)); -- -7 (A-B; 절댓값이 아님)
-- SELECT date_format(now(), "%Y-%m-%d %T");
-- SELECT time(now());
-- SELECT timediff(now(), date_format(now(), "%Y-%m-%d %T"));
/*
* START MISSION
*/
USE fastcampus;
/*
* Q6. 2020년 7월의 평균 DAU (Daily Active Users; 일일 활성 유저) 구하고,
* Active User의 증감 추세 확인하기
*/
-- date_format 기준에 따른 AU 계산
SELECT
date_format(substring(visited_at,1,10), "%Y-%m-%d") AS date,
count(DISTINCT customer_id) AS AU
FROM tbl_visit
GROUP BY 1;
-- 2020.07 평균 DAU
SELECT avg(AU) FROM (
SELECT
date_format(substring(visited_at,1,10), "%Y-%m-%d") AS date,
count(DISTINCT customer_id) AS AU
FROM tbl_visit
WHERE visited_at LIKE "2020-07%"
GROUP BY 1
) T;
-- 2020.07 DAU에 대한 7일 이동 평균
SELECT
date,
AVG(AU) OVER(ORDER BY date ROWS BETWEEN 6 PRECEDING AND CURRENT ROW) AS AU_7MA
FROM (
SELECT
date_format(substring(visited_at,1,10), "%Y-%m-%d") AS date,
count(DISTINCT customer_id) AS AU
FROM tbl_visit
WHERE visited_at LIKE "2020-07%"
GROUP BY 1
) AS T
LIMIT 31 OFFSET 6;
/*
* Q7. 2020년 7월 평균 WAU
*/
SELECT
date_format(substring(visited_at,1,10), "%U") AS y_week,
count(DISTINCT customer_id) AS AU
FROM tbl_visit
GROUP BY 1;
-- 한 주가 7일이 아닌 경우를 고려해서 앞/뒤 한 주씩 절삭하여 계산
SELECT avg(AU) FROM (
SELECT
date_format(substring(visited_at,1,10), "%U") AS y_week,
count(DISTINCT customer_id) AS AU
FROM tbl_visit
WHERE visited_at LIKE "2020-07%"
GROUP BY 1
LIMIT 3 OFFSET 1
) AS T;
/*
* Q8.2020년 7월의 DaiIy Revenue는 증가하는 추세인가요? 평균 DaiIy Revenue도 구해주세요.
* revenue를 구하는 방법: 우선 기준에 대해서 sum을 진행하고, 그 다음 avg를 진행한다.
*/
-- date_format 기준에 따른 total revenue 계산
SELECT
date_format(substring(purchased_at,1,10), "%Y-%m-%d") AS date,
sum(price) AS total_revenue
FROM tbl_purchase
GROUP BY 1;
-- 2020.07 total revenue에 대한 7일 이동 평균
SELECT
date,
avg(total_revenue) OVER(ORDER BY date ROWS BETWEEN 6 PRECEDING AND CURRENT ROW) AS total_revenue_7MA
FROM (
SELECT
date_format(substring(purchased_at,1,10), "%Y-%m-%d") AS date,
sum(price) AS total_revenue
FROM tbl_purchase
WHERE purchased_at LIKE "2020-07%"
GROUP BY 1
) AS T
LIMIT 31 OFFSET 6;
-- 2020.07 평균 total revenue
SELECT avg(total_revenue) FROM (
SELECT
date_format(substring(purchased_at,1,10), "%Y-%m-%d") AS date,
sum(price) AS total_revenue
FROM tbl_purchase
WHERE purchased_at LIKE "2020-07%"
GROUP BY 1
) AS T;
/*
* Q9.2020년 7월의 평균 WeekIy Revenue를 구해주세요
*/
SELECT
date_format(substring(purchased_at,1,10), "%Y-%m-%U") AS date,
sum(price) AS total_revenue
FROM tbl_purchase
GROUP BY 1;
-- 2020.07 평균 Weekly total revenue
-- 한 주가 7일이 아닌 경우를 고려해서 앞/뒤 한 주씩 절삭하여 계산
SELECT avg(total_revenue) FROM (
SELECT
date_format(substring(purchased_at,1,10), "%Y-%m-%U") AS date,
sum(price) AS total_revenue
FROM tbl_purchase
WHERE purchased_at LIKE "2020-07%"
GROUP BY 1
LIMIT 3 OFFSET 1
) AS T;
/*
* Q10.2020년 7월 요일별 Revenue를 구해주세요.어느 요일이 Revenue가 가장 높고 어느 요일이 Revenue가 가장 낮나요?
*/
SELECT
date_format(substring(purchased_at,1,10), "%Y-%m-%d") AS date,
sum(price) AS total_revenue
FROM tbl_purchase
GROUP BY 1;
-- 2020.07 요일별 평균 total revenue
-- %w와 %W는 출력 형식만 다를 뿐이라 일요일부터 순서대로 정렬할 때 idx 활용이 가능하다.
SELECT
date_format(date, "%w") AS idx,
date_format(date, "%W") AS weekday,
avg(total_revenue)
FROM (
SELECT
date_format(substring(purchased_at,1,10), "%Y-%m-%d") AS date,
sum(price) AS total_revenue
FROM tbl_purchase
WHERE purchased_at LIKE "2020-07%"
GROUP BY 1
) AS T
GROUP BY 1, 2
ORDER BY 3;
-- 2020.07 avg(total_revenue)는 토요일에 최소, 월요일에 최대이다.
/*
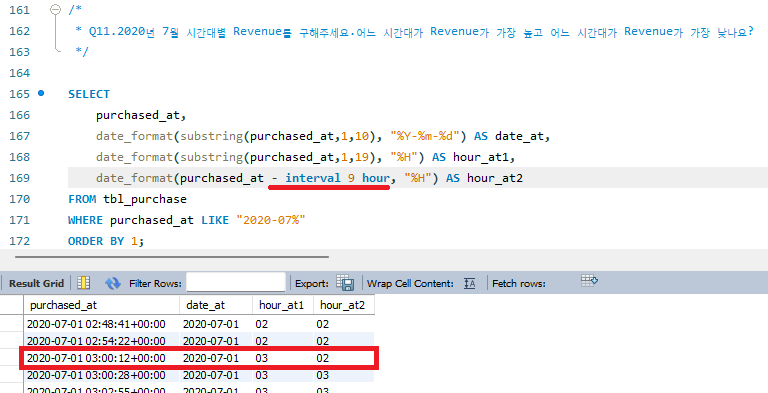
* Q11.2020년 7월 시간대별 Revenue를 구해주세요.
* 어느 시간대가 Revenue가 가장 높고 어느 시간대가 Revenue가 가장 낮나요?
*/
SELECT
purchased_at,
date_format(substring(purchased_at,1,10), "%Y-%m-%d") AS date_at,
date_format(substring(purchased_at,1,19), "%H") AS hour_at
-- ,date_format(purchased_at - interval 9 hour, "%H") AS hour_at2
FROM tbl_purchase
WHERE purchased_at LIKE "2020-07%"
ORDER BY 1;
SELECT
date_format(substring(purchased_at,1,10), "%Y-%m-%d") AS date_at,
date_format(substring(purchased_at,1,19), "%H") AS hour_at,
sum(price) AS revenue
FROM tbl_purchase
WHERE purchased_at LIKE "2020-07%"
GROUP BY 1, 2
ORDER BY 1, 2;
SELECT
hour_at,
avg(revenue)
FROM (
SELECT
date_format(substring(purchased_at,1,10), "%Y-%m-%d") AS date_at,
date_format(substring(purchased_at,1,19), "%H") AS hour_at,
sum(price) AS revenue
FROM tbl_purchase
WHERE purchased_at LIKE "2020-07%"
GROUP BY 1, 2
) AS T
GROUP BY 1
ORDER BY 2 DESC;
/*
* Q12.2020년 7월 요일 및 시간대별 Revenue를 구해주세요.
* 어느 요일 및 시간대가 Revenue가 가장 높고 어느 시간대가 Revenue가 가장 낮나요?
*/
SELECT
date_format(substring(purchased_at,1,10), "%Y-%m-%d") AS date_at,
date_format(substring(purchased_at,1,19), "%H") AS hour_at,
sum(price) AS revenue
FROM tbl_purchase
WHERE purchased_at LIKE "2020-07%"
GROUP BY 1, 2
ORDER BY 1, 2;
SELECT
date_format(date_at, "%w") AS idx,
date_format(date_at, "%W") AS weekday_at,
hour_at,
avg(revenue)
FROM (
SELECT
date_format(substring(purchased_at,1,10), "%Y-%m-%d") AS date_at,
date_format(substring(purchased_at,1,19), "%H") AS hour_at,
sum(price) AS revenue
FROM tbl_purchase
WHERE purchased_at LIKE "2020-07%"
GROUP BY 1, 2
) AS T
GROUP BY 1, 2, 3
ORDER BY 4 DESC;
/*
* Assignment.2020년 7월 요일 및 시간대별 AU
* 어느 요일 및 시간대가 AU가 가장 높고 어느 시간대가 AU가 가장 낮나요?
*/
SELECT
date_format(substring(visited_at,1,10), "%Y-%m-%d") AS date_at,
date_format(substring(visited_at,1,19), "%H") AS hour_at,
count(DISTINCT customer_id) AS AU
FROM tbl_visit
WHERE visited_at LIKE "2020-07%"
GROUP BY 1, 2
ORDER BY 1, 2;
SELECT
date_format(date_at, "%w") AS idx,
date_format(date_at, "%W") AS weekday_at,
hour_at,
avg(AU)
FROM (
SELECT
date_format(substring(visited_at,1,10), "%Y-%m-%d") AS date_at,
date_format(substring(visited_at,1,19), "%H") AS hour_at,
count(DISTINCT customer_id) AS AU
FROM tbl_visit
WHERE visited_at LIKE "2020-07%"
GROUP BY 1, 2
) AS T
GROUP BY 1, 2, 3
ORDER BY 4 DESC;
/*
* 시행 착오 기록
*/
-- ------------------------------------------------------------------------------------------
-- Q6.
-- 1차 시도 (오답): Day 1의 정답은 2657인데, 2674로 과대평가되었다.
-- SELECT day(visited_at), count(DISTINCT customer_id) FROM tbl_visit WHERE visited_at LIKE "2020-07%" GROUP BY 1;
-- 2020-07-01로 필터링된 데이터의 day에서 2가 발견되었다. day 함수에 대한 이해가 필요하다.
-- SELECT day(visited_at) FROM tbl_visit WHERE visited_at LIKE "2020-07-01%";
/*
* ERROR HANDLING
* RUN SCRIPT C:\Users\user\Downloads\sql_prac2_time_table_correction.sql
*/
-- 하지만 여전히 day 함수의 결과는 변함이 없다.
-- UTC와 KST 시차에 따라 값을 수정하거나 substring 함수를 활용한다.
-- 전체 일자의 DAU
SELECT
substring(visited_at,1,10) AS date,
count(DISTINCT customer_id) AS DAU
FROM tbl_visit
GROUP BY 1;
-- 2020년 7월의 DAU
SELECT
convert(substring(visited_at,9,2), UNSIGNED INT) AS m_day,
count(DISTINCT customer_id) AS DAU
FROM tbl_visit
WHERE visited_at LIKE "2020-07%"
GROUP BY 1;
SELECT
convert(substring(visited_at,9,2), UNSIGNED INT) AS m_day,
count(DISTINCT customer_id) AS DAU
FROM tbl_visit
WHERE visited_at LIKE "2020-07%"
GROUP BY 1;
-- 추가 시도 (오답): 2일차 DAU 2602인데, 2600으로 과소평가되었다.
-- SELECT
-- day(convert_tz(visited_at, "+09:00", "+00:00")) AS day,
-- count(DISTINCT customer_id) AS daily_active_users
-- FROM tbl_visit
-- WHERE visited_at LIKE "2020-07%" GROUP BY 1;
-- 평균 DAU
SELECT avg(daily_active_users) FROM (
SELECT
substring(visited_at,1,10) AS m_day,
count(DISTINCT customer_id) AS daily_active_users
FROM tbl_visit
WHERE visited_at LIKE "2020-07%" GROUP BY 1
) AS T;
/*
* 증감 추세 확인하기: 모든 레코드에 대해 평균값을 제하고 양수의 분포 확인하기
* 초반에는 음수가 많고, 후반에는 양수가 많으므로 증가하는 추세로 판단됨
*/
SELECT
convert(substring(visited_at,9,2), UNSIGNED INT) AS day,
count(DISTINCT customer_id) - 2692 AS daily_active_users
FROM tbl_visit
WHERE visited_at LIKE "2020-07%" GROUP BY 1;
SELECT
convert(substring(visited_at,9,2), UNSIGNED INT) AS day,
count(DISTINCT customer_id) - 2692 AS daily_active_users
FROM tbl_visit
WHERE visited_at LIKE "2020-07%" GROUP BY 1;
-- ------------------------------------------------------------------------------------------
-- ------------------------------------------------------------------------------------------
-- ------------------------------------------------------------------------------------------** UTC와 KST 시차로 연산 차이가 발생하는데, - interval 9 hour 연산 또는 substring을 통해 해결할 수 있다. 영상에서는 interval 연산을 사용했는데, 나는 정밀도 이슈로 정확한 연산이 수행되지 않는 문제가 존재했다. +00:00과 같은 시차 정보를 생략한 상태에서는 연산 결과가 정확하게 출력된다.
DAY 15
- LAG(col, n) OVER ( std: ORDER BY col (DESC) )
- (dense_)rank() OVER ( PARTITION BY col ORDER BY std (desc) )
SELECT DISTINCT * FROM tbl_customer;
-- Q13. 전체 유저의 Demographic
-- 성/연령별로 유저 숫자를 알려주세요. 어느 세그먼트가 가장 숫자가 많나요?
-- 참고로 F/M을 제외한 기타 성별은 하나로, 연령은 5세 단위로 적당히 묶어주시고, 세그먼트 숫자가 높은 순서대로 보여주세요
SELECT
CASE
WHEN length(gender) < 1 THEN 'Others'
ELSE gender
END AS gender,
CASE
WHEN age <= 15 THEN '0_15세 이하'
WHEN age <= 20 THEN '1_16-20세'
WHEN age <= 25 THEN '2_21-25세'
WHEN age <= 30 THEN '3_25-30세'
WHEN age <= 35 THEN '4_30-35세'
WHEN age <= 40 THEN '5_35-40세'
WHEN age <= 45 THEN '6_40-45세'
ELSE '7_45세 초과'
END AS age,
count(DISTINCT customer_id) AS users
FROM tbl_customer
GROUP BY 1,2
ORDER BY 3 DESC;
-- Q14. Q13 결과의 성 • 연령을 성별(연령)(ex. 남성(25-29세 이하)) 으로 통합해주시고,
-- 각 성 • 연령이 전체 고객에서 얼마나 차지하는지 분포(%)를 알려주세요. 역시 분포가 높은 순서대로 알려주세요
SELECT
concat(
CASE
WHEN length(gender) < 1 THEN '기타'
WHEN gender = "F" THEN '여성'
WHEN gender = "M" THEN '남성'
ELSE '기타'
END,
"(",
CASE
WHEN age <= 15 THEN '15세 이하'
WHEN age <= 20 THEN '16-20세'
WHEN age <= 25 THEN '21-25세'
WHEN age <= 30 THEN '25-30세'
WHEN age <= 35 THEN '30-35세'
WHEN age <= 40 THEN '35-40세'
WHEN age <= 45 THEN '40-45세'
ELSE '45세 초과'
END,
")"
) AS segment,
round(
count(DISTINCT customer_id)
/ (SELECT count(DISTINCT customer_id) FROM tbl_customer)
* 100, 2) AS "users_ratio (%)"
FROM tbl_customer
GROUP BY 1
ORDER BY 2 DESC;
-- Q15.2020년 7월의 성별에 대한 구매 건수와 총 Revenue를 구해주세요. 단, 남녀 이외의 성별은 하나로 묶어주세요
-- 성별은 tbl_customer
SELECT * FROM tbl_customer LIMIT 10;
-- 구매는 tbl_visit
SELECT * FROM tbl_purchase LIMIT 10;
-- 두 테이블을 합치자
SELECT
T1.*,
CASE WHEN length(T2.gender) < 1 THEN "기타"
WHEN T2.gender = "F" THEN "여성"
WHEN T2.gender = "M" THEN "남성"
ELSE "기타" END AS gender
FROM tbl_purchase AS T1
LEFT JOIN tbl_customer AS T2
ON T1.customer_id = T2.customer_id;
-- 성별에 대한 구매건수와 revenue 구하기
SELECT
gender,
count(*) AS cnt_purchase,
sum(price)
FROM (
SELECT
T1.*,
CASE WHEN length(gender) < 1 THEN "기타"
WHEN gender = "F" THEN "여성"
WHEN gender = "M" THEN "남성"
ELSE "기타" END AS gender
FROM tbl_purchase AS T1
LEFT JOIN tbl_customer AS T2
ON T1.customer_id = T2.customer_id
WHERE purchased_at LIKE "2020-07%"
) AS T
GROUP BY 1
ORDER BY 3 DESC;
-- Q16.2020년 7월의 성별/연령대에 따라 구매 건수와, 총 Revenue를 구해주세요. 남녀 이외의 성별은 하나로 묶어주세요
SELECT
CASE WHEN length(T2.gender) < 1 THEN "기타"
WHEN T2.gender = "F" THEN "여성"
WHEN T2.gender = "M" THEN "남성"
ELSE "기타"
END AS gender,
CASE
WHEN T2.age <= 15 THEN '15세 이하'
WHEN T2.age <= 20 THEN '16-20세'
WHEN T2.age <= 25 THEN '21-25세'
WHEN T2.age <= 30 THEN '25-30세'
WHEN T2.age <= 35 THEN '30-35세'
WHEN T2.age <= 40 THEN '35-40세'
WHEN T2.age <= 45 THEN '40-45세'
ELSE '45세 초과'
END AS age_group,
count(*) AS cnt,
sum(price) AS revenue
FROM tbl_purchase AS T1
LEFT JOIN tbl_customer AS T2
ON T1.customer_id = T2.customer_id
WHERE purchased_at LIKE "2020-07%"
GROUP BY 1, 2
ORDER BY 3 DESC;
-- Q17.2020년 7월 일별 매출과 증감폭, 증감률을 구해주세요
-- LAG(col, n) OVER (std: ORDER BY col (DESC))
WITH tbl_revenue AS (
SELECT
date_format(substr(purchased_at,1,10), "%Y-%m-%d") AS d_date,
sum(price) AS revenue
FROM tbl_purchase
WHERE substr(purchased_at,1,10) LIKE "2020-07%"
GROUP BY 1
)
SELECT *
, revenue - LAG(revenue) OVER(ORDER BY d_date asc) as rev_diff
, round((revenue - LAG(revenue,1) OVER(ORDER BY d_date asc)) / LAG(revenue) OVER(ORDER BY d_date asc) * 100,2) AS rev_ratio
FROM tbl_revenue;
-- Q18.2020년 7월 일별로 많이 구매한 고객들한테 소정의 선물을 줄려고해요
-- 7월에 일별로 구매 금액 기준으로 가장 많이 지출한 고객 Top3를 뽑아주세요
SELECT * FROM (
SELECT
date_format(substr(purchased_at,1,10), "%Y-%m-%d") AS d_date,
customer_id,
sum(price) AS revenue,
dense_rank() OVER (PARTITION BY date_format(substr(purchased_at,1,10), "%Y-%m-%d") ORDER BY sum(price) desc) AS rank_rev
FROM tbl_purchase WHERE purchased_at LIKE "2020-07%"
GROUP BY 1, 2
) AS T
WHERE rank_rev <= 3;DAY 16
-- Q19.2020년 7월 우리 신규유저가 하루 안에 결제로 넘어가는 비율이 어떻게 되나요? 그 비율이 어떤지
-- 알고싶고, 결제까지 보통 몇 분 정도가 소요되는지 알고싶어요.
-- 신규 유저의 가입일, 최초 구매일 (customer_id 기준으로 min(purchased_at))
-- time_to_sec, timediff
-- Q20.2020년 7월 우리 서비스는 유저의 재방문율이 높은 서비스인가요?
-- 이를 파악하기 위해 7월 기준 Day1 Retention이 어떤지 구해주시고 추세를 보기 위해 DaiIy로 추출해주세요.
-- Day-N Retention: 최근 방문일 대비 N일 이내로 재방문하는 경우
-- (SELF) JOIN
-- Q21. 우리 서비스는 신규유저가 많나요? 기존유저가 많나요? 가입기간별로 고객 분포가 어떤지 알려주세요
-- DAU 기준으로 부탁합니다. (Service age)
'Learn' 카테고리의 다른 글
| [패스트캠퍼스: Java&Spring 웹 개발] Week 2 - OOP Basic (0) | 2023.06.12 |
|---|---|
| [패스트캠퍼스: SQL 데이터 분석 첫걸음] Week 5 - 프로젝트 해커톤 (2) | 2023.06.07 |
| [패스트캠퍼스: SQL 데이터 분석 첫걸음] Week 3 - SQL 고급 기능 익히기 (0) | 2023.05.30 |
| [패스트캠퍼스: SQL 데이터 분석 첫걸음] Week 2 - SQL을 활용해 데이터 다루기 (0) | 2023.05.25 |
| [패스트캠퍼스: SQL 데이터 분석 첫걸음] Week 1 - SQL과 친해지기 (1) | 2023.05.24 |